Compiler Design

Compiler is a software that translates high level language into low level machine code (for processor).
UNIT 1
Language Processing System (LPS)
- Preprocessor → strips/expands directives → pure source code (HLL)
- Compiler → transforms source to assembly/machine code in several phases (lex, parse, semantic checks, IR, optimization, code generation) → assembly code (or directly object code)
- Assembler → translates assembly to object code (multiple relocatable m/c)
- Linker → merges object files/libraries, resolves symbols → executable (single m/c)
- Loader → places executable into memory, prepares to run. -> .exe
Preprocessors
Handles directives before compilation. (#include, #define in C/C++)
- Macro expansion (
#define→ inline code/text). - File inclusion (
#include→ copy/paste file content). - Conditional compilation (
#ifdef,#if, etc.).
No computation only substitution.
Compiler vs Interpreter
Files are in HDD. Compilers/interpreter in Main memory (RAM). And CPU handles execution.
Compiler
- Converts full source code into machine code (e.g., generates a .exe file).
- .exe runs independently without the compiler or source code.
- Faster execution post-compilation.
- Requires more space.
- Detects errors at compile-time (no execution).
- Typically platform-specific.
- C/C++.
Interpreter
- Executes code line-by-line; no standalone output file.
- Requires source code and interpreter at runtime.
- Slower execution due to on-the-fly translation.
- Detects errors during execution (previous lines have been executed).
- More portable across platforms if a compatible interpreter is available.
- Javascript (browser).
Phases of Compiler
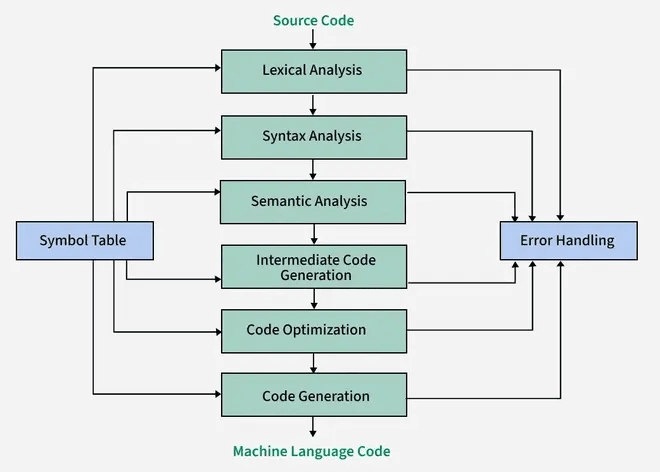
1. Lexical Analysis
- Converts a stream of characters (pure HLL i.e. ) into a stream of tokens using DFAs.
- All identifiers are stored in a symbol table after tokenization.
2. Syntax Analysis
- Parses tokens and builds a parse tree/AST (abstract syntax tree) using grammar rules.
3. Semantic Analysis
- Checks semantic rules (types, scopes, and context) to construct a semantically verified parse tree.
- Semantic Rules:
- Type checking.
- Undeclared variable detection.
- Multiple declaration prevention.
- Uses the symbol table to analyze in a bottom-up fashion.
4. Intermediate Code Generation
- Translates the AST into a platform-independent IR (Intermediate Representation).
- E.g., generates three-address code (TAC).
5. Code Optimization
- Refines the IR by eliminating redundancies and improving performance.
- Produces an optimized version of TAC.
6. Target Code Generation
- Converts the optimized IR into assembly/machine code (e.g., produces an executable).
These phases/functions do not run sequentially. Like code snippets, they are called upon whenever needed.
Error Handling: Detects invalid or unrecognized sequences and flags errors early in the compilation process.
Symbol Table Integration: Identifiers encountered during scanning are stored in a symbol table along with metadata (such as type and scope). This aids later phases in semantic analysis.
Lexical Analyzer
- Lexemes: The actual sequences of characters that form meaningful units (e.g.,
x,+,60). - Tokens: Pairs or tuples typically represented as
<token_type, token_value>(e.g.,<id, 1>,<operator, +>). - Patterns: Defined using regular expressions that specify the format of each token type (identifiers, numbers, keywords, etc.).
- Converts a raw stream of characters from the source code into a structured stream of tokens, which are easier for the parser to handle.
- Tokens include identifiers (variables, function names), operators (
+, =), keywords, symbols, literals, and constants (e.g., int, float). - LA eliminates comments and white spaces from program.
- Gives error message by providing row no. and column no.
Process Flow Example:
- Source Code:
x = y + z * 60 - Lexical Analysis: Reads characters, identifies lexemes (
x, =,y,+,z,*,60). - Generates tokens:
<id,1>,<assign>,<id,2>,<operator, +>,<id,3>,<operator, *>,<constant, 60>. - Stores identifiers (
x,y,z) in the symbol table withS.No, variable_name, type.
Count no. of tokens
- LA uses DFA to perform tokenization.
- During tokenization, LA always prioritizes longest matching.
- Doesn't care for syntax or semantic errors.
Example of tokens
int
main
{
"adsf asdf2343529 f"
93
i
=
0
;
return
)
,
++
<=
**c -> 3 tokens
in t -> 2 tokens
in/*comment line*/t -> same as above
=== -> 2 tokens
"hello -> token errorAmbiguous Grammar
A grammar is ambiguous if a string can have multiple valid derivation trees (via LMD or RMD). Example:
E -> E + E | id- The string
id + id + idcan be parsed in two different ways using only leftmost derivation.
Ambiguous to Unambiguous Grammar
Ensure a single, unique parse tree by enforcing operator precedence and associativity.
We need to process operators with higher precedence and associativity first. i.e. should be lower down the parse tree.
Eg: for E -> id + id + id
E -> E + E | id # is ambiguous
E -> E + id | id # unambiguous
Left recursive grammar since '+' operator has L->R associativity||ly for E -> id + id * id
E -> id + T | T
T -> T * id | id
Right recursive since '*' operator has higher precedencesRemove left recursion
Eg: L -> L + S | S
Becomes
L -> SA
A -> +SA | ERemoving left factoring
Eg: A -> aB1 | aB2 | aB3
Becomes
A -> AB
B -> B1 | B2 | B3Just take common prefix.
UNIT 2
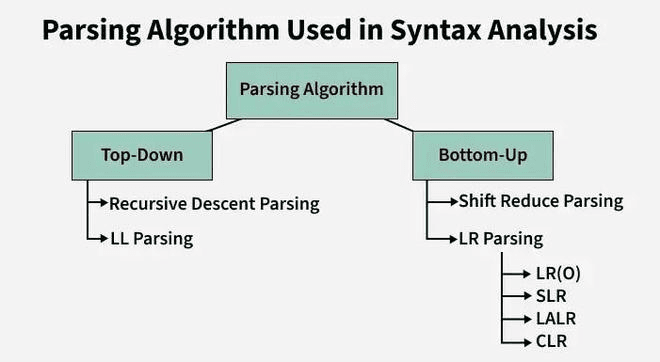
Parser (Syntax Analysis)
Transforms the stream of tokens into a structured, hierarchical parse tree or AST that represents the program's grammatical structure.
-
Top-Down Parsing:
- Uses recursive descent or LL(1) methods.
- Starts with the start symbol and breaks down the input via productions.
- Simple to implement but may require grammar modifications (e.g., eliminating left recursion).
-
Bottom-Up Parsing:
- Uses shift-reduce techniques like LR, SLR, LALR, or LR(1).
- Starts with the input tokens and reduces them to the start symbol.
- Handles a wider range of grammars with fewer modifications.
None accept ambiguous grammar.
LL(1)
- First L represents: reading left to right.
- Second L represents: LMD.
- (1) is for processing one token at a time.
Top-Down
- Derive word from start.
- Replace with .
- Hard to choose between .
- LMD
Bottom-Up
- Derive start from word.
- Replace with .
- RMD in reverse.
Recursive Descent Parser
- Top-Down Approach: Implements each non-terminal as a recursive function.
- Structure: Functions call one another based on grammar rules.
- Applicability: Works well for LL(1) grammars (no left recursion, clear first sets).
- Limitations: Cannot handle left-recursive grammars without modifications; may require backtracking for ambiguous rules.
First and Follow
FIRST Set
The set of terminals that can appear as the first symbol in some string derived from a non-terminal. Build bottom to top.
-
For a Terminal:
- Rule: If X is a terminal, then FIRST(X) = { X }.
-
For a Nonterminal:
- Rule: If X is a nonterminal, then FIRST(X) is the set of terminals that begin the strings derivable from X.
- Procedure:
- For every production X → Y₁ Y₂ ... Yₙ:
- Add all symbols in FIRST(Y₁) (except ε) to FIRST(X).
- If FIRST(Y₁) contains ε, then include FIRST(Y₂) (except ε).
- Continue this process until you reach a Yᵢ that does not derive ε, or you have processed all symbols.
- If all Yᵢ (i = 1 to n) derive ε, then add ε to FIRST(X).
- For every production X → Y₁ Y₂ ... Yₙ:
-
For the Empty String:
- Rule: If a nonterminal can derive the empty string (ε), then ε is included in its FIRST set.
FOLLOW Set
The first of what's immediately after every non-terminal's occurrence. Build top to bottom.
- Start Symbol:
- Rule: For the start symbol S, add the end-of-input marker `#core
Compiler is a software that translates high level language into low level machine code (for processor).
UNIT 1
Language Processing System (LPS)
- Preprocessor → strips/expands directives → pure source code (HLL)
- Compiler → transforms source to assembly/machine code in several phases (lex, parse, semantic checks, IR, optimization, code generation) → assembly code (or directly object code)
- Assembler → translates assembly to object code (multiple relocatable m/c)
- Linker → merges object files/libraries, resolves symbols → executable (single m/c)
- Loader → places executable into memory, prepares to run. -> .exe
Preprocessors
Handles directives before compilation. (#include, #define in C/C++)
- Macro expansion (
#define→ inline code/text). - File inclusion (
#include→ copy/paste file content). - Conditional compilation (
#ifdef,#if, etc.).
No computation only substitution.
Compiler vs Interpreter
Files are in HDD. Compilers/interpreter in Main memory (RAM). And CPU handles execution.
Compiler
- Converts full source code into machine code (e.g., generates a .exe file).
- .exe runs independently without the compiler or source code.
- Faster execution post-compilation.
- Requires more space.
- Detects errors at compile-time (no execution).
- Typically platform-specific.
- C/C++.
Interpreter
- Executes code line-by-line; no standalone output file.
- Requires source code and interpreter at runtime.
- Slower execution due to on-the-fly translation.
- Detects errors during execution (previous lines have been executed).
- More portable across platforms if a compatible interpreter is available.
- Javascript (browser).
Phases of Compiler
1. Lexical Analysis
- Converts a stream of characters (pure HLL i.e. ) into a stream of tokens using DFAs.
- All identifiers are stored in a symbol table after tokenization.
2. Syntax Analysis
- Parses tokens and builds a parse tree/AST (abstract syntax tree) using grammar rules.
3. Semantic Analysis
- Checks semantic rules (types, scopes, and context) to construct a semantically verified parse tree.
- Semantic Rules:
- Type checking.
- Undeclared variable detection.
- Multiple declaration prevention.
- Uses the symbol table to analyze in a bottom-up fashion.
4. Intermediate Code Generation
- Translates the AST into a platform-independent IR (Intermediate Representation).
- E.g., generates three-address code (TAC).
5. Code Optimization
- Refines the IR by eliminating redundancies and improving performance.
- Produces an optimized version of TAC.
6. Target Code Generation
- Converts the optimized IR into assembly/machine code (e.g., produces an executable).
These phases/functions do not run sequentially. Like code snippets, they are called upon whenever needed.
Error Handling: Detects invalid or unrecognized sequences and flags errors early in the compilation process.
Symbol Table Integration: Identifiers encountered during scanning are stored in a symbol table along with metadata (such as type and scope). This aids later phases in semantic analysis.
Lexical Analyzer
- Lexemes: The actual sequences of characters that form meaningful units (e.g.,
x,+,60). - Tokens: Pairs or tuples typically represented as
<token_type, token_value>(e.g.,<id, 1>,<operator, +>). - Patterns: Defined using regular expressions that specify the format of each token type (identifiers, numbers, keywords, etc.).
- Converts a raw stream of characters from the source code into a structured stream of tokens, which are easier for the parser to handle.
- Tokens include identifiers (variables, function names), operators (
+, =), keywords, symbols, literals, and constants (e.g., int, float). - LA eliminates comments and white spaces from program.
- Gives error message by providing row no. and column no.
Process Flow Example:
- Source Code:
x = y + z * 60 - Lexical Analysis: Reads characters, identifies lexemes (
x, =,y,+,z,*,60). - Generates tokens:
<id,1>,<assign>,<id,2>,<operator, +>,<id,3>,<operator, *>,<constant, 60>. - Stores identifiers (
x,y,z) in the symbol table withS.No, variable_name, type.
Count no. of tokens
- LA uses DFA to perform tokenization.
- During tokenization, LA always prioritizes longest matching.
- Doesn't care for syntax or semantic errors.
Example of tokens
int
main
{
"adsf asdf2343529 f"
93
i
=
0
;
return
)
,
++
<=
**c -> 3 tokens
in t -> 2 tokens
in/*comment line*/t -> same as above
=== -> 2 tokens
"hello -> token errorAmbiguous Grammar
A grammar is ambiguous if a string can have multiple valid derivation trees (via LMD or RMD). Example:
E -> E + E | id- The string
id + id + idcan be parsed in two different ways using only leftmost derivation.
Ambiguous to Unambiguous Grammar
Ensure a single, unique parse tree by enforcing operator precedence and associativity.
We need to process operators with higher precedence and associativity first. i.e. should be lower down the parse tree.
Eg: for E -> id + id + id
E -> E + E | id # is ambiguous
E -> E + id | id # unambiguous
Left recursive grammar since '+' operator has L->R associativity||ly for E -> id + id * id
E -> id + T | T
T -> T * id | id
Right recursive since '*' operator has higher precedencesRemove left recursion
Eg: L -> L + S | S
Becomes
L -> SA
A -> +SA | ERemoving left factoring
Eg: A -> aB1 | aB2 | aB3
Becomes
A -> AB
B -> B1 | B2 | B3Just take common prefix.
UNIT 2
Parser (Syntax Analysis)
Transforms the stream of tokens into a structured, hierarchical parse tree or AST that represents the program's grammatical structure.
-
Top-Down Parsing:
- Uses recursive descent or LL(1) methods.
- Starts with the start symbol and breaks down the input via productions.
- Simple to implement but may require grammar modifications (e.g., eliminating left recursion).
-
Bottom-Up Parsing:
- Uses shift-reduce techniques like LR, SLR, LALR, or LR(1).
- Starts with the input tokens and reduces them to the start symbol.
- Handles a wider range of grammars with fewer modifications.
None accept ambiguous grammar.
LL(1)
- First L represents: reading left to right.
- Second L represents: LMD.
- (1) is for processing one token at a time.
Top-Down
- Derive word from start.
- Replace with .
- Hard to choose between .
- LMD
Bottom-Up
- Derive start from word.
- Replace with .
- RMD in reverse.
Recursive Descent Parser
- Top-Down Approach: Implements each non-terminal as a recursive function.
- Structure: Functions call one another based on grammar rules.
- Applicability: Works well for LL(1) grammars (no left recursion, clear first sets).
- Limitations: Cannot handle left-recursive grammars without modifications; may require backtracking for ambiguous rules.
First and Follow
FIRST Set
The set of terminals that can appear as the first symbol in some string derived from a non-terminal. Build bottom to top.
-
For a Terminal:
- Rule: If X is a terminal, then FIRST(X) = { X }.
-
For a Nonterminal:
- Rule: If X is a nonterminal, then FIRST(X) is the set of terminals that begin the strings derivable from X.
- Procedure:
- For every production X → Y₁ Y₂ ... Yₙ:
- Add all symbols in FIRST(Y₁) (except ε) to FIRST(X).
- If FIRST(Y₁) contains ε, then include FIRST(Y₂) (except ε).
- Continue this process until you reach a Yᵢ that does not derive ε, or you have processed all symbols.
- If all Yᵢ (i = 1 to n) derive ε, then add ε to FIRST(X).
- For every production X → Y₁ Y₂ ... Yₙ:
-
For the Empty String:
- Rule: If a nonterminal can derive the empty string (ε), then ε is included in its FIRST set.
FOLLOW Set
The first of what's immediately after every non-terminal's occurrence. Build top to bottom.
-
Start Symbol:
- Rule: For the start symbol S, add the end-of-input marker to FOLLOW(S).
-
For Productions:
- Rule: For every production A → αBβ:
- Add all non-ε symbols in FIRST(β) to FOLLOW(B).
- If β can derive ε (i.e., FIRST(β) contains ε) or if B is at the end of the production, add FOLLOW(A) to FOLLOW(B).
- Rule: For every production A → αBβ:
-
For Productions Ending with a Nonterminal:
- Rule: If a production is of the form A → αB (i.e., B is the last symbol), then add FOLLOW(A) to FOLLOW(B).
LL(1) Parser
A top-down parser that scans input Left-to-right, produces a Leftmost derivation, and uses 1-token lookahead.
Grammar Requirements:
- Must be free of left recursion.
- Should be left-factored to avoid ambiguity.
Building the LL(1) Parsing Table:
- For each production A → α:
- For every terminal a in FIRST(α), add A → α to table entry M[A, a].
- If ε ∈ FIRST(α), then for every terminal b in FOLLOW(A), add A → α to M[A, b].
- Keep putting on right hand side as long as NULL and add firsts.
- Include M[A, ∈ FOLLOW(A).
- The table must have at most one production per cell; conflicts indicate the grammar is not LL(1).

Parsing Process:
- Initialize a stack with the start symbol and end marker `#core
Compiler is a software that translates high level language into low level machine code (for processor).
UNIT 1
Language Processing System (LPS)
- Preprocessor → strips/expands directives → pure source code (HLL)
- Compiler → transforms source to assembly/machine code in several phases (lex, parse, semantic checks, IR, optimization, code generation) → assembly code (or directly object code)
- Assembler → translates assembly to object code (multiple relocatable m/c)
- Linker → merges object files/libraries, resolves symbols → executable (single m/c)
- Loader → places executable into memory, prepares to run. -> .exe
Preprocessors
Handles directives before compilation. (#include, #define in C/C++)
- Macro expansion (
#define→ inline code/text). - File inclusion (
#include→ copy/paste file content). - Conditional compilation (
#ifdef,#if, etc.).
No computation only substitution.
Compiler vs Interpreter
Files are in HDD. Compilers/interpreter in Main memory (RAM). And CPU handles execution.
Compiler
- Converts full source code into machine code (e.g., generates a .exe file).
- .exe runs independently without the compiler or source code.
- Faster execution post-compilation.
- Requires more space.
- Detects errors at compile-time (no execution).
- Typically platform-specific.
- C/C++.
Interpreter
- Executes code line-by-line; no standalone output file.
- Requires source code and interpreter at runtime.
- Slower execution due to on-the-fly translation.
- Detects errors during execution (previous lines have been executed).
- More portable across platforms if a compatible interpreter is available.
- Javascript (browser).
Phases of Compiler
1. Lexical Analysis
- Converts a stream of characters (pure HLL i.e. ) into a stream of tokens using DFAs.
- All identifiers are stored in a symbol table after tokenization.
2. Syntax Analysis
- Parses tokens and builds a parse tree/AST (abstract syntax tree) using grammar rules.
3. Semantic Analysis
- Checks semantic rules (types, scopes, and context) to construct a semantically verified parse tree.
- Semantic Rules:
- Type checking.
- Undeclared variable detection.
- Multiple declaration prevention.
- Uses the symbol table to analyze in a bottom-up fashion.
4. Intermediate Code Generation
- Translates the AST into a platform-independent IR (Intermediate Representation).
- E.g., generates three-address code (TAC).
5. Code Optimization
- Refines the IR by eliminating redundancies and improving performance.
- Produces an optimized version of TAC.
6. Target Code Generation
- Converts the optimized IR into assembly/machine code (e.g., produces an executable).
These phases/functions do not run sequentially. Like code snippets, they are called upon whenever needed.
Error Handling: Detects invalid or unrecognized sequences and flags errors early in the compilation process.
Symbol Table Integration: Identifiers encountered during scanning are stored in a symbol table along with metadata (such as type and scope). This aids later phases in semantic analysis.
Lexical Analyzer
- Lexemes: The actual sequences of characters that form meaningful units (e.g.,
x,+,60). - Tokens: Pairs or tuples typically represented as
<token_type, token_value>(e.g.,<id, 1>,<operator, +>). - Patterns: Defined using regular expressions that specify the format of each token type (identifiers, numbers, keywords, etc.).
- Converts a raw stream of characters from the source code into a structured stream of tokens, which are easier for the parser to handle.
- Tokens include identifiers (variables, function names), operators (
+, =), keywords, symbols, literals, and constants (e.g., int, float). - LA eliminates comments and white spaces from program.
- Gives error message by providing row no. and column no.
Process Flow Example:
- Source Code:
x = y + z * 60 - Lexical Analysis: Reads characters, identifies lexemes (
x, =,y,+,z,*,60). - Generates tokens:
<id,1>,<assign>,<id,2>,<operator, +>,<id,3>,<operator, *>,<constant, 60>. - Stores identifiers (
x,y,z) in the symbol table withS.No, variable_name, type.
Count no. of tokens
- LA uses DFA to perform tokenization.
- During tokenization, LA always prioritizes longest matching.
- Doesn't care for syntax or semantic errors.
Example of tokens
int
main
{
"adsf asdf2343529 f"
93
i
=
0
;
return
)
,
++
<=
**c -> 3 tokens
in t -> 2 tokens
in/*comment line*/t -> same as above
=== -> 2 tokens
"hello -> token errorAmbiguous Grammar
A grammar is ambiguous if a string can have multiple valid derivation trees (via LMD or RMD). Example:
E -> E + E | id- The string
id + id + idcan be parsed in two different ways using only leftmost derivation.
Ambiguous to Unambiguous Grammar
Ensure a single, unique parse tree by enforcing operator precedence and associativity.
We need to process operators with higher precedence and associativity first. i.e. should be lower down the parse tree.
Eg: for E -> id + id + id
E -> E + E | id # is ambiguous
E -> E + id | id # unambiguous
Left recursive grammar since '+' operator has L->R associativity||ly for E -> id + id * id
E -> id + T | T
T -> T * id | id
Right recursive since '*' operator has higher precedencesRemove left recursion
Eg: L -> L + S | S
Becomes
L -> SA
A -> +SA | ERemoving left factoring
Eg: A -> aB1 | aB2 | aB3
Becomes
A -> AB
B -> B1 | B2 | B3Just take common prefix.
UNIT 2
Parser (Syntax Analysis)
Transforms the stream of tokens into a structured, hierarchical parse tree or AST that represents the program's grammatical structure.
-
Top-Down Parsing:
- Uses recursive descent or LL(1) methods.
- Starts with the start symbol and breaks down the input via productions.
- Simple to implement but may require grammar modifications (e.g., eliminating left recursion).
-
Bottom-Up Parsing:
- Uses shift-reduce techniques like LR, SLR, LALR, or LR(1).
- Starts with the input tokens and reduces them to the start symbol.
- Handles a wider range of grammars with fewer modifications.
None accept ambiguous grammar.
LL(1)
- First L represents: reading left to right.
- Second L represents: LMD.
- (1) is for processing one token at a time.
Top-Down
- Derive word from start.
- Replace with .
- Hard to choose between .
- LMD
Bottom-Up
- Derive start from word.
- Replace with .
- RMD in reverse.
Recursive Descent Parser
- Top-Down Approach: Implements each non-terminal as a recursive function.
- Structure: Functions call one another based on grammar rules.
- Applicability: Works well for LL(1) grammars (no left recursion, clear first sets).
- Limitations: Cannot handle left-recursive grammars without modifications; may require backtracking for ambiguous rules.
First and Follow
FIRST Set
The set of terminals that can appear as the first symbol in some string derived from a non-terminal. Build bottom to top.
-
For a Terminal:
- Rule: If X is a terminal, then FIRST(X) = { X }.
-
For a Nonterminal:
- Rule: If X is a nonterminal, then FIRST(X) is the set of terminals that begin the strings derivable from X.
- Procedure:
- For every production X → Y₁ Y₂ ... Yₙ:
- Add all symbols in FIRST(Y₁) (except ε) to FIRST(X).
- If FIRST(Y₁) contains ε, then include FIRST(Y₂) (except ε).
- Continue this process until you reach a Yᵢ that does not derive ε, or you have processed all symbols.
- If all Yᵢ (i = 1 to n) derive ε, then add ε to FIRST(X).
- For every production X → Y₁ Y₂ ... Yₙ:
-
For the Empty String:
- Rule: If a nonterminal can derive the empty string (ε), then ε is included in its FIRST set.
FOLLOW Set
The first of what's immediately after every non-terminal's occurrence. Build top to bottom.
- Start Symbol:
- Rule: For the start symbol S, add the end-of-input marker `#core
Compiler is a software that translates high level language into low level machine code (for processor).
UNIT 1
Language Processing System (LPS)
- Preprocessor → strips/expands directives → pure source code (HLL)
- Compiler → transforms source to assembly/machine code in several phases (lex, parse, semantic checks, IR, optimization, code generation) → assembly code (or directly object code)
- Assembler → translates assembly to object code (multiple relocatable m/c)
- Linker → merges object files/libraries, resolves symbols → executable (single m/c)
- Loader → places executable into memory, prepares to run. -> .exe
Preprocessors
Handles directives before compilation. (#include, #define in C/C++)
- Macro expansion (
#define→ inline code/text). - File inclusion (
#include→ copy/paste file content). - Conditional compilation (
#ifdef,#if, etc.).
No computation only substitution.
Compiler vs Interpreter
Files are in HDD. Compilers/interpreter in Main memory (RAM). And CPU handles execution.
Compiler
- Converts full source code into machine code (e.g., generates a .exe file).
- .exe runs independently without the compiler or source code.
- Faster execution post-compilation.
- Requires more space.
- Detects errors at compile-time (no execution).
- Typically platform-specific.
- C/C++.
Interpreter
- Executes code line-by-line; no standalone output file.
- Requires source code and interpreter at runtime.
- Slower execution due to on-the-fly translation.
- Detects errors during execution (previous lines have been executed).
- More portable across platforms if a compatible interpreter is available.
- Javascript (browser).
Phases of Compiler
1. Lexical Analysis
- Converts a stream of characters (pure HLL i.e. ) into a stream of tokens using DFAs.
- All identifiers are stored in a symbol table after tokenization.
2. Syntax Analysis
- Parses tokens and builds a parse tree/AST (abstract syntax tree) using grammar rules.
3. Semantic Analysis
- Checks semantic rules (types, scopes, and context) to construct a semantically verified parse tree.
- Semantic Rules:
- Type checking.
- Undeclared variable detection.
- Multiple declaration prevention.
- Uses the symbol table to analyze in a bottom-up fashion.
4. Intermediate Code Generation
- Translates the AST into a platform-independent IR (Intermediate Representation).
- E.g., generates three-address code (TAC).
5. Code Optimization
- Refines the IR by eliminating redundancies and improving performance.
- Produces an optimized version of TAC.
6. Target Code Generation
- Converts the optimized IR into assembly/machine code (e.g., produces an executable).
These phases/functions do not run sequentially. Like code snippets, they are called upon whenever needed.
Error Handling: Detects invalid or unrecognized sequences and flags errors early in the compilation process.
Symbol Table Integration: Identifiers encountered during scanning are stored in a symbol table along with metadata (such as type and scope). This aids later phases in semantic analysis.
Lexical Analyzer
- Lexemes: The actual sequences of characters that form meaningful units (e.g.,
x,+,60). - Tokens: Pairs or tuples typically represented as
<token_type, token_value>(e.g.,<id, 1>,<operator, +>). - Patterns: Defined using regular expressions that specify the format of each token type (identifiers, numbers, keywords, etc.).
- Converts a raw stream of characters from the source code into a structured stream of tokens, which are easier for the parser to handle.
- Tokens include identifiers (variables, function names), operators (
+, =), keywords, symbols, literals, and constants (e.g., int, float). - LA eliminates comments and white spaces from program.
- Gives error message by providing row no. and column no.
Process Flow Example:
- Source Code:
x = y + z * 60 - Lexical Analysis: Reads characters, identifies lexemes (
x, =,y,+,z,*,60). - Generates tokens:
<id,1>,<assign>,<id,2>,<operator, +>,<id,3>,<operator, *>,<constant, 60>. - Stores identifiers (
x,y,z) in the symbol table withS.No, variable_name, type.
Count no. of tokens
- LA uses DFA to perform tokenization.
- During tokenization, LA always prioritizes longest matching.
- Doesn't care for syntax or semantic errors.
Example of tokens
int
main
{
"adsf asdf2343529 f"
93
i
=
0
;
return
)
,
++
<=
**c -> 3 tokens
in t -> 2 tokens
in/*comment line*/t -> same as above
=== -> 2 tokens
"hello -> token errorAmbiguous Grammar
A grammar is ambiguous if a string can have multiple valid derivation trees (via LMD or RMD). Example:
E -> E + E | id- The string
id + id + idcan be parsed in two different ways using only leftmost derivation.
Ambiguous to Unambiguous Grammar
Ensure a single, unique parse tree by enforcing operator precedence and associativity.
We need to process operators with higher precedence and associativity first. i.e. should be lower down the parse tree.
Eg: for E -> id + id + id
E -> E + E | id # is ambiguous
E -> E + id | id # unambiguous
Left recursive grammar since '+' operator has L->R associativity||ly for E -> id + id * id
E -> id + T | T
T -> T * id | id
Right recursive since '*' operator has higher precedencesRemove left recursion
Eg: L -> L + S | S
Becomes
L -> SA
A -> +SA | ERemoving left factoring
Eg: A -> aB1 | aB2 | aB3
Becomes
A -> AB
B -> B1 | B2 | B3Just take common prefix.
UNIT 2
Parser (Syntax Analysis)
Transforms the stream of tokens into a structured, hierarchical parse tree or AST that represents the program's grammatical structure.
-
Top-Down Parsing:
- Uses recursive descent or LL(1) methods.
- Starts with the start symbol and breaks down the input via productions.
- Simple to implement but may require grammar modifications (e.g., eliminating left recursion).
-
Bottom-Up Parsing:
- Uses shift-reduce techniques like LR, SLR, LALR, or LR(1).
- Starts with the input tokens and reduces them to the start symbol.
- Handles a wider range of grammars with fewer modifications.
None accept ambiguous grammar.
LL(1)
- First L represents: reading left to right.
- Second L represents: LMD.
- (1) is for processing one token at a time.
Top-Down
- Derive word from start.
- Replace with .
- Hard to choose between .
- LMD
Bottom-Up
- Derive start from word.
- Replace with .
- RMD in reverse.
Recursive Descent Parser
- Top-Down Approach: Implements each non-terminal as a recursive function.
- Structure: Functions call one another based on grammar rules.
- Applicability: Works well for LL(1) grammars (no left recursion, clear first sets).
- Limitations: Cannot handle left-recursive grammars without modifications; may require backtracking for ambiguous rules.
First and Follow
FIRST Set
The set of terminals that can appear as the first symbol in some string derived from a non-terminal. Build bottom to top.
-
For a Terminal:
- Rule: If X is a terminal, then FIRST(X) = { X }.
-
For a Nonterminal:
- Rule: If X is a nonterminal, then FIRST(X) is the set of terminals that begin the strings derivable from X.
- Procedure:
- For every production X → Y₁ Y₂ ... Yₙ:
- Add all symbols in FIRST(Y₁) (except ε) to FIRST(X).
- If FIRST(Y₁) contains ε, then include FIRST(Y₂) (except ε).
- Continue this process until you reach a Yᵢ that does not derive ε, or you have processed all symbols.
- If all Yᵢ (i = 1 to n) derive ε, then add ε to FIRST(X).
- For every production X → Y₁ Y₂ ... Yₙ:
-
For the Empty String:
- Rule: If a nonterminal can derive the empty string (ε), then ε is included in its FIRST set.
FOLLOW Set
The first of what's immediately after every non-terminal's occurrence. Build top to bottom.
-
Start Symbol:
- Rule: For the start symbol S, add the end-of-input marker to FOLLOW(S).
-
For Productions:
- Rule: For every production A → αBβ:
- Add all non-ε symbols in FIRST(β) to FOLLOW(B).
- If β can derive ε (i.e., FIRST(β) contains ε) or if B is at the end of the production, add FOLLOW(A) to FOLLOW(B).
- Rule: For every production A → αBβ:
-
For Productions Ending with a Nonterminal:
- Rule: If a production is of the form A → αB (i.e., B is the last symbol), then add FOLLOW(A) to FOLLOW(B).
LL(1) Parser
A top-down parser that scans input Left-to-right, produces a Leftmost derivation, and uses 1-token lookahead.
Grammar Requirements:
- Must be free of left recursion.
- Should be left-factored to avoid ambiguity.
Building the LL(1) Parsing Table:
- For each production A → α:
- For every terminal a in FIRST(α), add A → α to table entry M[A, a].
- If ε ∈ FIRST(α), then for every terminal b in FOLLOW(A), add A → α to M[A, b].
- Keep putting on right hand side as long as NULL and add firsts.
- Include M[A, ∈ FOLLOW(A).
- The table must have at most one production per cell; conflicts indicate the grammar is not LL(1).
Parsing Process:
- Initialize a stack with the start symbol and end marker .
- Read the lookahead token.
- If top of stack is:
- A terminal matching the lookahead: Pop it and advance the input.
- A nonterminal: Consult the table; push the production’s right-hand side (in reverse order) if found.
- An error if no matching entry exists.
- Repeat until the stack is empty and input is fully consumed.

Error Handling: When a table entry is empty, report a syntax error and apply recovery strategies if needed. Advantages: Simple, efficient, and easy to implement for LL(1) grammars. Limitations: Only works with grammars that are LL(1); may require grammar modifications for others.
Steps to Check if a Grammar is LL(1):

Bottom Up Parser
- Processes input left-to-right, constructing a rightmost derivation in reverse.
- Uses shift (push tokens onto a stack) and reduce (collapse symbols using grammar productions) operations.
- Typically driven by a parsing table (ACTION and GOTO) and a stack.
- Capable of handling more complex grammars than many top-down methods.
- Can work with left recursive and non-deterministic grammar. No backtracking.
LR(0)
A type of bottom-up parsing that uses LR(0) items—productions with a dot indicating how much of the production has been seen (shifted).
LR(0) Items
- A production with a dot (·) indicating parsing progress.
- Example: For
A → BC, items are:[A → · BC][A → B · C][A → BC ·]
closure(I)
- Start with a set of LR(0) items I.
- For each item
[A → α · B β]in I, add[B → · γ]for every productionB → γ. - Repeat until no new items can be added (included added productions).
goto(I, X)
- For each item
[A → α · X β]in I, move the dot past X to form[A → α X · β]. - Collect all such items into a new set J.
- Apply closure(J) to get goto(I, X).
LR(0) Parsing Table Construction
- Augment Grammar:
- Add .
- Build States:
- Start with .
- For each state , compute for every symbol to generate new states.
- ACTION Table: (contains shift and reduce operations over terminal)
- If an item in is , set ACTION[I, a] to "shift to ".
- If an item in is , for every terminal , set ACTION[I, t] to "reduce by ".
- For containing , set ACTION[I, $] to "accept".
- GOTO Table: (contains only shift operations over non-terminals)
- For each nonterminal , if has an item , set GOTO[I, B] to .
- Conflict Check:
- Ensure each cell in the tables has only one action; multiple actions mean the grammar is not LR(0).
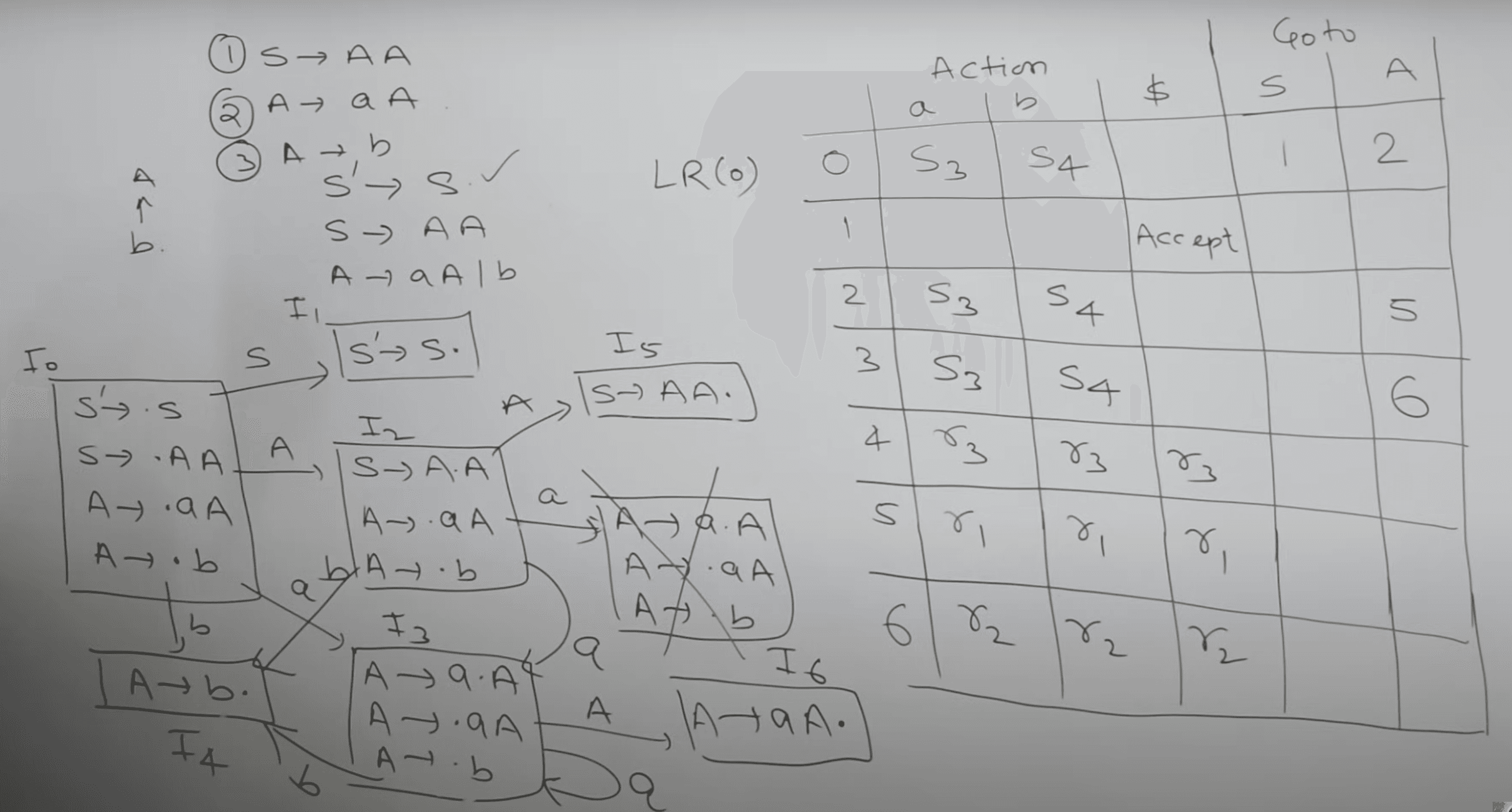
- Initialize:
- Stack: [0]
- Append $$to input.
- Repeat until done:
- Let current state = top of stack; current token = lookahead.
- Shift (push):
- If ACTION[state, token] = "shift s":
- Push token, then state s.
- Advance input.
- If ACTION[state, token] = "shift s":
- Reduce (pop):
- If ACTION[state, token] = "reduce by A → α":
- Pop 2×|α| items (double length of RHS).
- Let t = new top (number); push nonterminal A, then push .
- If ACTION[state, token] = "reduce by A → α":
- Accept/Error:
- If ACTION[state,$$ ] = "accept": parsing succeeds.
- Otherwise, if no valid action, signal error.
- End:
- Parsing completes when the accept action is reached.

Shift items together if same goto non-terminal.
SLR(1) Parsing
SLR(1) (Simple LR with 1 lookahead) extends LR(0) by using FOLLOW sets to decide reduce actions.
SLR(1) Parsing is built the same way as LR(0) parsing, with one key difference.
For an item , instead of reducing on all terminals, add a reduce action only for terminals in .
LR(0) SLR(1) but not vice-versa.
[!Tip] Inadequate State: Any state where there exists either (shift-reduce) or conflict.
CLR(1)
Most powerful LR Parser with look ahead symbols. Same as SLR(1) just calculate FOLLOW of each production at runtime.
- Build Canonical LR(1) Items:
- Items are of the form , where is a lookahead.
- Closure: For , add for every production and each . (find follow of first B, right next to dot which called it, and no other occurrence)
- Goto: For each item , shift the dot over to form , then take closure. (carry previous follow)
Fill the table just like we did in SLR(1) just use calculated follow for reduction.
LALR(1)
Minimized from of CLR(1). Less powerful. We merge same states with different look ahead symbols.

Operator Precedence Grammar
An operator precedence grammar is a CFG where productions do not have adjacent nonterminals, allowing clear specification of precedence and associativity among terminal operators.
- Precedence Relations:
- Equal Precedence ( ): Operators at the same level.
- Lower Precedence ( ): The left operator yields to the right operator.
- Higher Precedence ( ): The left operator takes precedence over the right.
- Parsing Mechanism:
- A parser uses a precedence table based on these relations to decide when to shift (read new input) or reduce (apply a production), especially for arithmetic expressions.
- Advantages & Limitations:
- Advantages: Simple and efficient for expressions with defined operator hierarchies.
- Limitations: Applicable only to grammars meeting specific constraints (e.g., no adjacent nonterminals, no ε-productions).
UNIT 3
Syntax Directed Translation (SDT) = Grammar + Semantic Rules + Semantic Actions
With grammar we give meaningful rules. Apart from semantic analysis SDT is also used in-
- Code Generation
- Intermediate code generation
- Value in symbol table
- Expression evaluation
- Converting infix to post fix
You will be given grammar and a string. Grammar will have semantic rules as code snippets {print("+");}. You'll have to built a parse tree and solve it bottom up to print the final answer.Attributes
Attach relevant information like strings, numbers, types, memory locations, or code fragments to grammar symbols of a language, which are used as labels for nodes in parse tree.
The value of each attribute at parse tree node is determined by semantic rules associated with production applied at that node, defining the context-specific information for language construct.
Classification of Attributes
Based on process of evaluation of values, attributes are classified into two types-
| Synthesized Attributes | Inherited Attributes |
|---|---|
| Parse tree node value is determined by attributes value at child nodes. | Parse tree node value is determined by attributes value at parent and/or left-sibling node. |
| Pass information in a Bottom-up fashion | Top-down or across the parse tree |
| Eg: evaluating value of expression or size of data type | Eg: evaluating expected data type of a child node or environment |
| Bottom-up parses like LALR or SLR | Top-down parsing like LL |
| Don't require context from parent | Require context from parent or surrounding nodes to be computed. |
| S-Attributed SDT | L-Attributes SDT |
|---|---|
| Uses only synthesized attributes | Uses both inherited and synthesized attributes. |
| Semantic actions are placed at extreme right of production | Semantic actions are placed anywhere on RHS of production |
| Attributes are evaluated during Bottom-up parsing | Attributes are evaluated by traversing parse tree depth first left to right |
Intermediate Code Generation
ICG in compilers creates a machine-independent, low-level representation of source code, facilitating optimization and making compiler design more modular. This abstraction layer allows for
- Portability - easier adaptation of compiler to different machine architectures.
- Optimization Opportunities - more efficient target code through ICG
- Easy of Compiler Construction - simplifies development and maintenance of compiler by making things modular.
Convert to Postfix
If c
then x
else
y
e ? x y --> e x y ?Three Address Code
TAC is a type of intermediate code where each instruction can have at most 3 operands and one operator. i.e. .
It simplifies complex operations into sequence of simple statements, supporting various operators of arithmetic, logic or boolean operations.
Eg: into
t1 = a + b
t2 = a + b
t3 = t2 + c
t4 = t1 * t3Types of TAC
| Instruction | Syntax |
|---|---|
| Assignment Statement | X = y op z |
| Assignment Instruction | X = op y |
| Copy Statement | X = y |
| Unconditional Jump | goto L |
| Conditional Jump | if x relop y goto L |
| Procedure Call | Parm x1 <br> Parm x2 <br> … <br> Parm xn <br> Call p,n <br> Return y |
| Array Statement | X = y[i] <br> X[i] = y |
| Address and Pointer Assignment | X = &y <br> X = *y |
Representation
Quadruplets
| # | op | arg1 | arg2 | result |
|---|---|---|---|---|
| 1 | + | a | b | t1 |
| 2 | * | t1 | c | t2 |
| 3 | = | t2 | x |
Triplets
- Result is stores in variable of sequence number
- Advantage: Space isn't wasted
- Disadvantage: Statements can't be moved
| # | op | arg1 | arg2 |
|---|---|---|---|
| 1 | + | a | b |
| 2 | * | (1) | c |
| 3 | = | (2) | x |
Here
(i)means “use the result of tripleti” (i.e.tᵢ).
Indirect Triplet
- Triplet can be separated by order of execution and using pointers
- Advantage: statement can be moved
- Disadvantage: two memory access
Pointer Table
| idx | ptr |
|---|---|
| 1 | →3 |
| 2 | →1 |
| 3 | →2 |
Triplet Table
| # | op | arg1 | arg2 |
|---|---|---|---|
| 1 | + | a | b |
| 2 | * | (1) | c |
| 3 | = | (2) | x |
Execution order follows the Pointer Table (1→3→2), allowing reordering without renumbering triplets.
Binary Tree Generation thingy

Definitions
- Syntax Tree: Abstract representation of syntactic structure of program, omitting brackets and punctuations. (concise version of parse tree)
- Parse Tree: Detailed tree diagram showing all syntactical elements of a program.
- Annotated Parse Tree: A parse tree enhanced with additional information like values, types, or variable bindings. Useful for semantic analysis and code generation.
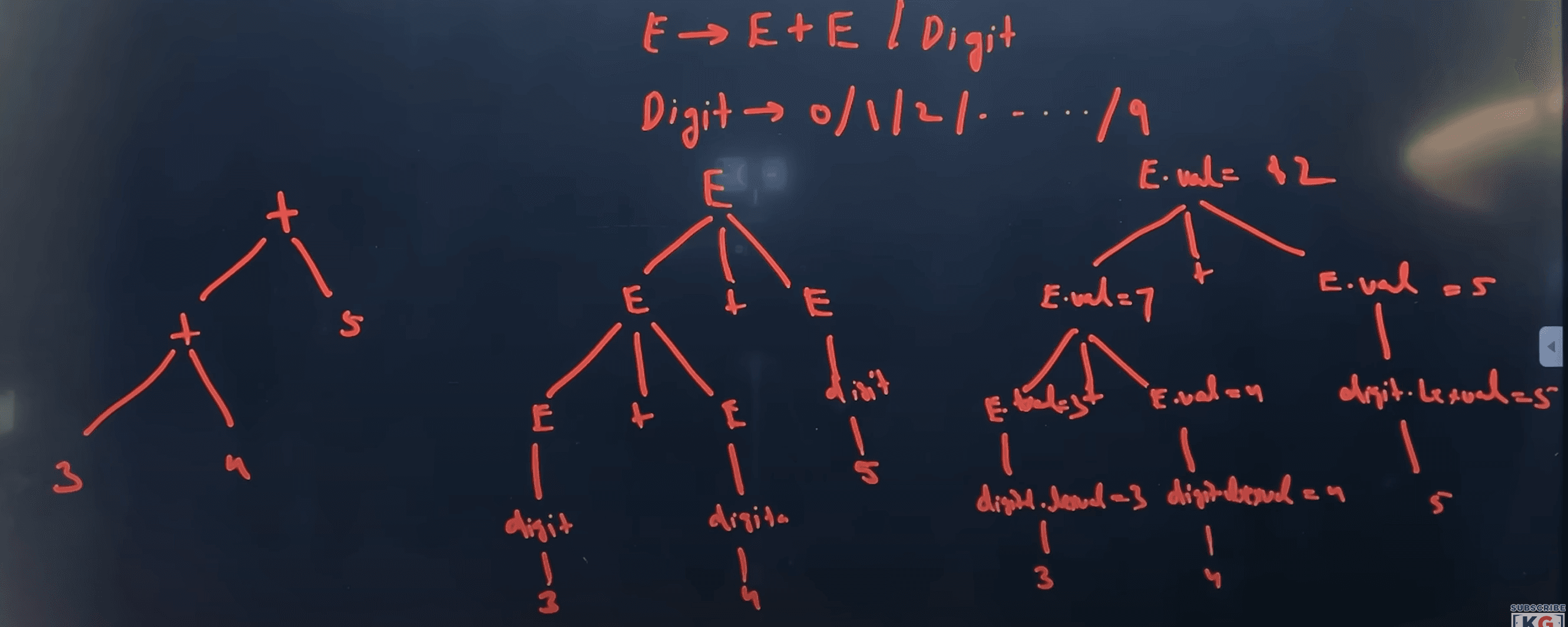
SDT of Boolean Expression
| Production | Semantic Actions |
|---|---|
| E → E₁ OR E₂ | E.place = newtemp();<br>Emit(E.place = E₁.place 'or' E₂.place); |
| E → E₁ AND E₂ | E.place = newtemp();<br>Emit(E.place = E₁.place 'and' E₂.place); |
| E → NOT E₁ | E.place = newtemp();<br>Emit(E.place = 'not' E₁.place); |
| E → (E₁) | E.place = E₁.place; |
| E → TRUE | E.place = newtemp();<br>Emit(E.place = '1'); |
| E → FALSE | E.place = newtemp();<br>Emit(E.place = '0'); |
Study STD for flow control and switch casing
UNIT 4
Symbol Table
Data structure used by compiler to store information about the source program's variables, functions, constants, user-defined types and other identifiers.
Need
- It helps the compiler track the scope, life, and attributes (like type, size, value) of each identifier.
- It is essential for semantic analysis, type checking, and code generation.
Analysis phase of compiler (Frontend) - lexical, syntax, semantic analysis, ICG Synthesis phase of compiler (Backend) - Code optimization, Target Code Generation
The information is collected by the analysis phases of the compiler and used by the synthesis phases of the compiler.
- Lexical Analysis - Creates new table entries
- Syntax Analysis - Adds information about attributes types, scope and use in table
- Semantic Analysis - To check expression are semantically correct and type checking
- Intermediate Code Generation - Helps in adding temporary variable information in code.
- Code Optimization - Used for machine dependent optimization
- Code Generation - Uses address information of identifier present in table for code generation.
Information used by compiler from symbol table
- Data type and name
- Declaring procedure (function declaration)
- Pointer to structure table
- Parameter passing by value or by reference
- No. and types of argument passed to function
- Base address
Essential functions of a symbol table - Lookup, insert, access, modify, delete
Important symbol table requirements - Adaptive Structure, Quick Lookup/Search, Space-efficient, Language feature accommodation.
Data Structures for Symbol Table
1. Linear List
A Linear List is a simple data structure where elements (such as identifiers or symbols) are stored sequentially, typically in an array or linked list.
Characteristics:
- Sequential search is used to locate symbols.
- Insertion is easy but search time is O(n) in the worst case.
- Best suited for small symbol tables.
Advantages:
- Simple to implement.
- No overhead of complex data structures.
Disadvantages:
- Inefficient for large symbol tables due to linear search time.
2. Search Tree
A Search Tree (commonly a Binary Search Tree or BST) organizes symbols in a hierarchical manner based on a comparison function (usually alphabetical order).
Characteristics:
- Average time complexity for search, insert, and delete is O(log n) (if balanced).
- Nodes represent symbols with pointers to left/right subtrees.
Advantages:
- Faster lookups compared to a linear list.
- Maintains order among symbols.
Disadvantages:
- If not balanced, performance can degrade to O(n).
- Slightly more complex to implement.
Variants:
- AVL Tree
- Red-Black Tree
3. Hash Table
A Hash Table is a data structure that stores key-value pairs using a hash function to compute an index into an array of buckets or slots.
Characteristics:
- Expected O(1) time for search, insert, and delete.
- Collisions are handled using techniques like:
- Chaining
- Open addressing (e.g., linear probing, quadratic probing)
Advantages:
- Very fast access time for large symbol tables.
- Efficient memory usage with proper hash function and load factor.
Disadvantages:
- Performance depends on the quality of the hash function.
- Collisions can degrade performance.
Scope
Scope defines where in program an identifier (variable / function) is valid and accessible. (language dependent)
Symbol Table maintains uniqueness of each identifier's declaration and scope-related semantic rules.
- Scope of variables in statement blocks.
{ int a; ...} - Scope of formal arguments of functions.
int func(int n) {...}
| Aspect | Lexical Scoping | Dynamic Scoping |
|---|---|---|
| Determination Time | At compile time. | At runtime. |
| Scope Basis | Location in source code. | Calling sequence of functions. |
| Predictability | High; scope is clear from code structure. | Low; depends on program’s execution path. |
| Variable Accessibility | Determined by code blocks and functions. | Influenced by function call order. |
| Common Usage | Preferred in most modern languages. | Less common; found in older languages. |
Activation Record
The activation record is crucial for handling data necessary for a procedure's single execution. When a procedure is called, this record is pushed onto the stack, and it's removed once control returns to the calling function.
procedure refers to a reusable block of code that performs a specific task, while record refers to a data structure that groups related data items together.
- Local Data: Variables and data used only within that procedure.
- Temporaries: Short‑lived storage for intermediate calculation results.
- Saved Machine Status: The CPU state (e.g., Program counter, registers) saved before the call.
- Control Link: A pointer back to the caller’s activation record. (what functions is called inside)
- Access Link: A pointer to activation records that hold non‑local data. (where the function is defined)
- Actual Parameters: The inputs the caller gives to the procedure when calling it.
- Return Value: The value a procedure sends back to its caller.
Memory-allocation Methods in Compilation
- Code Storage
- Contains fixed-size, unchanging executable target code during compilation.
- Static Allocation
- Stores when formation of data objects is not possible at run time.
- Object-size known at compile time.
- Heap Allocation (methods->)
- Garbage Collection
- Garbage objects (that persist after losing all access paths) are identified and returned to free space for reuse.
- Reference Counting
- Each heap cell has a counter tracking no. of references to it.
- Reclaims heap storage elements as soon as they become inaccessible and counter is adjusted.
- Garbage Collection
- Stack Allocation
- Manages data-structures known as Activation Records
- They Pushed at call time and popped when call ends (with local variables).
1. Static Allocation
Definition
Static Allocation is a storage allocation method where memory for all variables is allocated at compile time. The addresses of all variables are known before the program is executed.
Characteristics
- Each variable is assigned a fixed memory location during compilation.
- No allocation or deallocation during runtime.
- Suitable for programs with no recursion and fixed-size data.
When is it Used?
- In simple languages or early-stage compilers.
- For global variables or constants.
- In embedded systems with limited memory.
Advantages
- Simple to implement.
- No runtime overhead for memory allocation or deallocation.
- Fast access due to fixed memory addresses.
Disadvantages
- Inefficient memory usage: memory is reserved even if variables are not used.
- No support for recursion: each recursive call needs a separate instance of variables.
- Lack of flexibility: cannot handle dynamic data structures like linked lists, trees, etc.
Example
int x; // memory for x is allocated at compile time
float y; // memory for y is allocated at compile time2. Dynamic Allocation
Definition
Dynamic Allocation is a storage allocation method where memory is allocated at runtime, typically from the heap. It is used for data structures whose size or lifetime cannot be determined at compile time.
Characteristics
- Memory is allocated and deallocated manually by the programmer or automatically via the runtime environment.
- Enables creation of dynamic data structures such as:
- Linked lists
- Trees
- Graphs
- Allocation is done using system/library functions like
malloc(),calloc()in C/C++, ornewin Java.
When is it Used?
- When data sizes are unknown until runtime.
- In applications requiring dynamic memory management, such as interpreters or systems with unpredictable input size.
- For objects and structures with variable lifetime.
Advantages
- Efficient memory usage: memory is allocated only when needed.
- Supports complex and flexible data structures.
- Recursion and variable-sized data are handled easily.
Disadvantages
- More complex implementation.
- May lead to memory leaks if deallocation is not done properly.
- Slower access time compared to static or stack allocation.
- Requires garbage collection or manual memory management.
Example in C
int* ptr = (int*) malloc(sizeof(int)); // dynamically allocates memory
*ptr = 10;
free(ptr); // deallocates the memoryIn the symbol table:
- Only the type information may be stored initially.
- Actual memory location is determined and stored at runtime.
3. Hybrid Allocation
Definition
Hybrid Allocation is a combination of two or more memory allocation strategies — static, stack, and dynamic (heap) — to leverage the advantages of each and reduce their limitations.
It is the most commonly used approach in modern compilers and runtime systems.
Characteristics
- Static allocation is used for global/static variables and constants.
- Stack allocation is used for local variables with predictable lifetimes (e.g., function calls).
- Dynamic allocation (heap) is used for variable-size or user-defined data structures with unpredictable lifetimes.
Why Use Hybrid Allocation?
- To provide efficiency, flexibility, and recursion support.
- To optimize memory usage based on the nature of data and lifetime of variables.
Memory Segments in a Hybrid System
- Code Segment – Stores program instructions (read-only).
- Data Segment (Static) – Stores global/static variables.
- Stack Segment – Stores function call information and local variables.
- Heap Segment – Stores dynamically allocated memory.
Example (C/C++)
int x = 5; // static/global segment
void func() {
int y = 10; // stack segment
int* ptr = malloc(4); // heap segment
free(ptr);
}Advantages
- Combines speed of static and stack allocation with the flexibility of dynamic allocation.
- Efficient use of memory based on variable type and lifetime.
- Supports recursion, dynamic structures, and predictable memory.
Disadvantages
- More complex to implement and manage.
- Requires careful coordination between compiler and runtime system.
- Possibility of memory fragmentation in the heap.
Hash Functions in Symbol Table
Mid-Square Method (Hash Function)
The Mid-Square Method is a hashing technique in which the key is squared, and then a portion from the middle digits of the result is extracted as the hash value.
This method works well when the keys are numeric and relatively uniformly distributed.
Steps Involved
- Square the key (
k). - Extract the middle r digits from the squared number.
- Apply modulo with the table size (if needed) to keep the value within bounds.
Example
Let’s take a key k = 123:
- Square the key: 123^2 = 15129
- Extract middle digits: If we want 2 middle digits (assuming 5-digit number), we take
51. - Hash value: h(k) = 51 If the table size is, say, 100:h(k) = 51 mod 100 = 51
Characteristics
- Works best when key values are not clustered.
- Better than simple modulo methods for certain data distributions.
- Suitable for numeric keys.
Advantages
- Simple to implement.
- Tends to give better distribution than division for small keys.
- Reduces the effect of patterns in the keys.
Disadvantages
- Choice of "middle digits" can affect performance.
- Squaring can be costly for very large keys.
- Less effective for alphanumeric or long string keys.
Folding method
The Folding Method is a hashing technique where the key is divided into parts, and those parts are combined (usually by addition or XOR) to compute the hash value.
This method is particularly useful when keys are long numbers or strings.
Steps Involved
- Divide the key into equal-sized parts (usually groups of digits or characters).
- Combine the parts using:
- Addition
- XOR (bitwise)
- Any consistent mathematical operation
- Apply modulo with the hash table size (if needed).
Example (Using Addition)
Let the key be: 12345678
Assume we split it into parts of 4 digits: 1234 and 5678
- Add the parts: 1234 + 5678 = 6912
- If table size
m = 100, then: h(k) = 6912 mod 100 = 12
Folding by Boundary Reverse (Variant)
If parts are folded by reversing alternate parts:
Key: 12345678
Split: 1234, 5678 → reverse 5678 → 8765
Now,
1234 + 8765 = 9999
h(k) = 9999 mod 100 = 99
Advantages
- Easy to implement.
- Works well for both numeric and character-based keys.
- Reduces the impact of repeated patterns in data.
Disadvantages
- Choice of partitioning can affect performance.
- May still lead to collisions if parts are similar or repetitive.
Best Use Case
- When keys are long identifiers, like memory addresses or long numeric strings.
- When keys contain repeating patterns.
Division Method (Hash Function)
Definition
The Division Method is one of the simplest and most commonly used hashing techniques.
It computes the hash value by taking the remainder of the division of the key by the table size.
Formula h(k) = k mod m
Where:
h(k)is the hash value,kis the key (usually a numeric representation of the symbol),mis the size of the hash table (preferably a prime number to reduce collisions).
Example
Let the key k = 1234, and the table size m = 13.
Then: h(1234) = 1234 mod 13 = 12
So, the key 1234 will be placed in slot 12 of the hash table.
Choosing m (Table Size)
- Should be a prime number not too close to a power of 2.
- Helps in spreading the keys more uniformly.
- Avoid values of
mthat are multiples of common patterns in keys (e.g., 10, 100, etc.).
Advantages
- Very simple and fast to compute.
- Efficient for integer keys.
- Easy to implement in both hardware and software.
Disadvantages
- Performance highly depends on a good choice of
m. - Poor distribution if
mis not chosen wisely (e.g., ifmis even or not prime). - Vulnerable to clustering if keys share a common factor with
m.
UNIT 5
Code Generation is the process of converting IR of source code into target code (assembly level). Which is also optimized. Same high-level code will have different generated machine code for different platforms. (x86, ARM, etc).
Optimization - process of reducing execution time of a code without effecting outcome of source program.
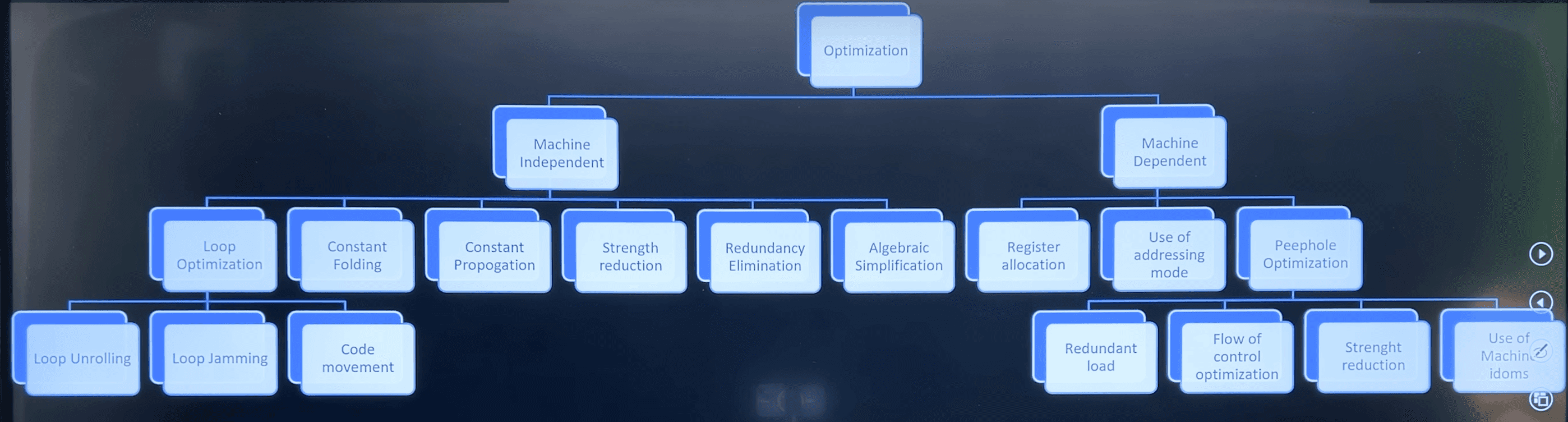
Machine Independent Optimization - not specific to processor or architecture. Focuses on logic and efficiency. Highly portable.
Loop Optimization
Loop optimization encompasses various compiler transformations to make loops more efficient by reducing overhead, improving data locality, and exposing parallelism.
- To apply loop optimization, we must first detect loops.
- For detecting loops, we use control flow analysis (CFA) using program flow graph (PFG).
- To find PFG, we need to find basic blocks.
- A Basic block is a sequence of 3-address statements where control enters at the beginning and leaves only at the end without any jumps or halts.
In order to find the basic blocks, we need to finds the leader in the program then a basic block will start from one leader to the next leader but not including next leader.
Identifying leaders in a basic block
- First statement is a leader.
- Statement that is the target of conditional or unconditional statement is a leader.
goto(9)- 9th line is leader. - Statement that follow immediately a conditional or unconditional statement is a leader.

Loop Jamming
Loop jamming, also known as loop fusion, is a compiler optimization technique that combines two adjacent loops that iterate over the same index range into a single loop. This can improve performance by reducing loop overhead, enhancing data locality, and lowering instruction dispatch costs.
// Original code with two separate loops
for (int i = 0; i < n; ++i) {
A[i] = B[i] + C[i];
}
for (int i = 0; i < n; ++i) {
D[i] = A[i] * 2;
}
// Fused loop
for (int i = 0; i < n; ++i) {
A[i] = B[i] + C[i];
D[i] = A[i] * 2;
}Loop Unrolling
Loop unrolling is a simple optimization that replicates the loop body multiple times to reduce the loop overhead (branching and index updates) and increase instruction-level parallelism.
Example:
// Original loop
int i = 1;
while (i <= 100) {
print(i);
i++;
}
// Unrolled by factor of 2
int i = 1;
while (i <= 100) {
print(i);
i++;
print(i);
i++;
}Code Movement (Loop invariant computation)
Moves computations that yield the same result on every iteration out of the loop. This reduces redundant work inside the loop and can significantly improve performance.
// Before code motion
for (int i = 0; i < n; ++i) {
int t = a + b; // loop-invariant computation
X[i] = t * C[i];
}
// After code motion
int t = a + b; // moved outside the loop
for (int i = 0; i < n; ++i) {
X[i] = t * C[i];
}Machine Independent Code Optimization
Constant Folding
Replacing value of expression before compilation.
x = a + 2 * 3 + 4
// optimized
x = a + 10Constant Propagation
Replacing value of constant before compilation.
const int pi = 3.1415
int x = 360 / pi
// optimized
int x = 360 / 3.145Strength Reduction
Replacing the costly operations by cheaper.
y = x ^ 2 ==> y = x * x
y = x * 2 ==> y = x + x
y = x / 2 ==> y = x >> 1Redundant Code Elimination / Common Subexpression elimination
Avoiding the evaluation of any expression more than once.
x = a + b
y = b + a
// optimized
y = xAlgebra Simplification
x + 0 ==> x
x * 1 ==> xPeephole Optimization - Machine Dependent
A peephole pass scans short instruction sequences (“windows”) and replaces them with faster or shorter equivalents.
Workflow
- Slide a small window (2–5 instructions) over the instruction stream.
- Match known inefficient patterns.
- Replace with optimized sequence.
Simple Example
;; Before
MOV R1, <span style={{ color: 'rgb(116,62,228)' }}>#0</span> ; R1 ← 0
ADD R1, R1, R2 ; R1 ← R1 + R2
;; After
MOV R1, R2 ; direct moveCommon Patterns
- Redundant Load/Store Elimination
- Strength Reduction: e.g.
mul <span style={{ color: 'rgb(116,62,228)' }}>#8</span>→lsl <span style={{ color: 'rgb(116,62,228)' }}>#3</span> - Branch Simplification: invert or combine jumps
- Instruction Combining: fuse shift+add into a single “LEA”‑style op (on x86)
Directed Acyclic Graph (DAG)
A Directed Acyclic Graph represents computations in a basic block so that common subexpressions, dead code, and invariant code become immediately apparent.
Construction
- Parse each statement/expression in the block.
- Lookup or Create a node for each operand or operator:
- If an identical node already exists → reuse it.
- Otherwise → create it.
- Link operand nodes → result node with directed edges.
- Bind variable names to nodes; on reassignment, update the binding.
Example
// Original
t1 = a + b;
t2 = a + b;
t3 = t1 * c;
x = t2 * c;| Node | Computation | |
|---|---|---|
| N0 | a | |
| N1 | b | |
| N2 | a + b | ← reused for t1 and t2 |
| N3 | c | |
| N4 | N2 * N3 | ← reused for t3 and x |
Resulting code:
t1 = a + b;
t3 = t1 * c;
x = t3;Advantages
- Common‑Subexpression Elimination: identical computations mapped to one node
- Dead‑Code Detection: prune nodes not reaching any output
- Invariant Detection: nodes without incoming dependencies can be hoisted
- Liveness Exposure: clearer use‑def chains aid register allocation
Algebraic Rewrites in a DAG
By applying commutativity and associativity, the DAG can be restructured to expose more sharing, constant‑folding, and strength‑reduction opportunities.
Key Laws
- Commutativity:
a + b == b + a,a * b == b * a - Associativity:
(a + b) + c == a + (b + c), same for*
Reordering Example
y = a * b * c;- Original DAG:
- N0=
a, N1=b, N2=c - N3=
N0 * N1 - N4=
N3 * N2
- N0=
- Re-associated:
- N5=
N1 * N2 - N6=
N0 * N5 - If
b*crecurs, N5 is shared.
- N5=
Resulting code:
tmp1 = b * c;
y = a * tmp1;Benefits
- Fewer temporaries
- Early constant folding (e.g. if
c==1) - Exposes strength reduction (e.g. multiplying by powers of two)
UNIT 6
Objectives of Error Handling
- Identify errors and provide clear, useful diagnostics.
- Ensuring error handling doesn't delay compilation time too much.
Lexical Phase Error Occurs when a sequence of character doesn't form a recognizable token.
Syntactic Phase Error Syntax error occur due to coding mistake by programmers. Like missing semicolon.
Semantic Error Incorrect use of programming statement, leading to meaninglessness. Like missing variable declaration.
Features of an Error Reporter
The Error Reporter is a crucial component of a compiler responsible for identifying, reporting, and helping recover from errors in the source code.
-
Accuracy
- Should report the correct type and location of errors.
- Helps the programmer quickly identify and fix the issue.
-
Clarity
- Error messages should be clear, concise, and user-friendly.
- Should avoid cryptic or overly technical terms.
-
Consistency
- Should use a uniform format for reporting different kinds of errors.
- Makes it easier for users to understand and locate issues.
-
Multiple Error Reporting
- Should attempt to report as many errors as possible in a single pass, rather than stopping at the first one.
- Helps in comprehensive debugging.
-
Error Classification
- Should distinguish between different types of errors:
- Lexical errors
- Syntax errors
- Semantic errors
- Runtime errors
- Should distinguish between different types of errors:
-
Position Indication
- Should show line numbers, column numbers, or even highlight the offending token.
-
Suggestive Messages
- May provide possible corrections or hints to resolve the error.
-
Support for Recovery
- Should integrate with error recovery mechanisms (like panic mode or phrase-level recovery) to continue parsing after an error is detected.
Error Recovery Strategies
When an error is detected during compilation, the compiler must recover and continue processing to detect further errors. This is essential for generating useful feedback to the programmer.
The following are major error recovery strategies:
1. Panic Mode Recovery
Description:
- The parser discards input tokens until a synchronizing token (like
;,}, orend) is found. - It then resumes parsing from that point.
Characteristics:
- Simple and fast.
- Guarantees that parsing continues.
- May skip large parts of the input and miss subsequent errors.
Example:
int x = 10 // missing semicolon
printf("Value");Parser skips tokens until it finds ; or printf.
2. Phrase-Level Recovery
Description:
- The parser performs local corrections to the input, such as:
- Inserting a missing token
- Deleting an extra token
- Replacing a token with another
- It tries to repair the error and continue parsing.
Characteristics:
- More precise than panic mode.
- Might introduce incorrect assumptions about the program.
- Increases compiler complexity.
3. Error Productions
Description:
- The grammar is augmented with additional rules that account for common errors.
- When such a rule is matched, the parser generates a specific error message.
Characteristics:
- Helps in catching frequent or known mistakes early.
- Requires knowledge of typical errors.
- Increases grammar size and complexity.
Example:
stmt → if ( expr ) stmt | error ) stmtCatches missing opening parenthesis in if statements.
4. Global Correction
Description:
- The compiler analyzes the entire input and makes minimum changes to transform it into a valid program.
- Uses algorithms to compute the smallest set of insertions, deletions, or replacements.
Characteristics:
- Highly accurate but computationally expensive.
- Not commonly implemented in real-world compilers.
- More useful in theoretical models or teaching tools.
| Strategy | Description | Accuracy | Complexity | Used In Practice |
|---|---|---|---|---|
| Panic Mode | Skip tokens until synchronizing point | Low | Low | Yes |
| Phrase-Level | Local corrections (insert/delete) | Medium | Medium | Yes |
| Error Productions | Add rules for common errors | Medium | Medium | Sometimes |
| Global Correction | Minimal edits for valid input | High | High | Rarely |
Lex vs Yacc
| Feature | Lex | Yacc |
|---|---|---|
| Full Form | Lexical Analyzer | Yet Another Compiler Compiler |
| Purpose | Used for lexical analysis (tokenizing) | Used for syntax analysis (parsing) |
| Input | Regular Expressions | Context-Free Grammar |
| Output | C code for lexical analyzer | C code for syntax parser |
| Generates | yylex() function | yyparse() function |
| Used For | Breaking source code into tokens | Checking the grammatical structure of tokens |
| Input File Extension | .l | .y |
| Integration | Works with Yacc (provides tokens) | Works with Lex (receives tokens) |
| Token Handling | Identifies tokens and returns token codes | Receives tokens and builds parse tree |
| Grammar Support | Regular expressions | Context-free grammar |
| Tool Type | Scanner Generator | Parser Generator |
| Common Language | C (output is in C code) | C (output is in C code) |
How They Work Together
- Lex reads input and matches patterns defined using regular expressions.
- On finding a token, it returns it to Yacc.
- Yacc uses these tokens to match grammar rules and build the parse tree or abstract syntax tree (AST).
Example Workflow
[Lex source (.l)] → Lex → C code for scanner → Token stream
[Tokens] → Yacc parser (.y) → Yacc → C code for parser → Parse Tree